
In her CoD Summit 2023 presentation, Fission co-founder and CTO Brooklyn Zelenka discusses the need for location-independent compute, and how content addressing and open protocols are making it possible.
We're Living in a Server-Centric World
Since the invention of the LAMP stack in the '90s, we've been working with a server-centric model. It has led to developers specializing in front-end, back-end, DevOps, Kubernetes, Docker, and more. Over the years, it has become more difficult to train and maintain this complex system.
Amazon, Microsoft, and Google control the majority of data centers, which has led to further centralization. In places like South America, Central America, and Africa, the lack of compute infrastructure means that users in these areas have less access to resources.
IoT, compute over data, and LLMs cannot work long-term if we keep sending data to a small number of data centers. It's an overwhelming, massive amount of data.
We have to bring compute to where the data is produced, closer to the user.
Building a New Compute Stack
We know we need location-independent compute and data, but to do this in production, you first need location-independent auth.
A capability-based model like UCAN removes the authorization server, simplifying permissions handling. We no longer need pristine APIs for everything and can pass around auth as necessary.
The direction and the layout of the requests become the flow of authority.
Not only is it more efficient and energy-saving, but it's also more resilient because there is no central server that can bring the rest of the network down if it goes offline.
Now that auth is handled, we can solve for location-independent compute.
We started with WebAssembly because you can write in any language you want, and it runs anywhere and deterministically.
When running a computation, we take arguments and apply them to a Wasm function. This outputs a CID or content identifier. When computation runs over these CIDs, new CIDs are output.
This means we can compute over that content-addressed data without needing a centralized server!
We can roll all of this and a scheduler up into a task and run it, and when it executes, it returns a receipt. The receipt includes pure values (EX: 1 + 1 = 2), effects (something you want to happen next that needs to take resources off the network, like sending an email), and metadata.
Input Addressing
With content addressing, we take data, hash it, and use that data as the key value.
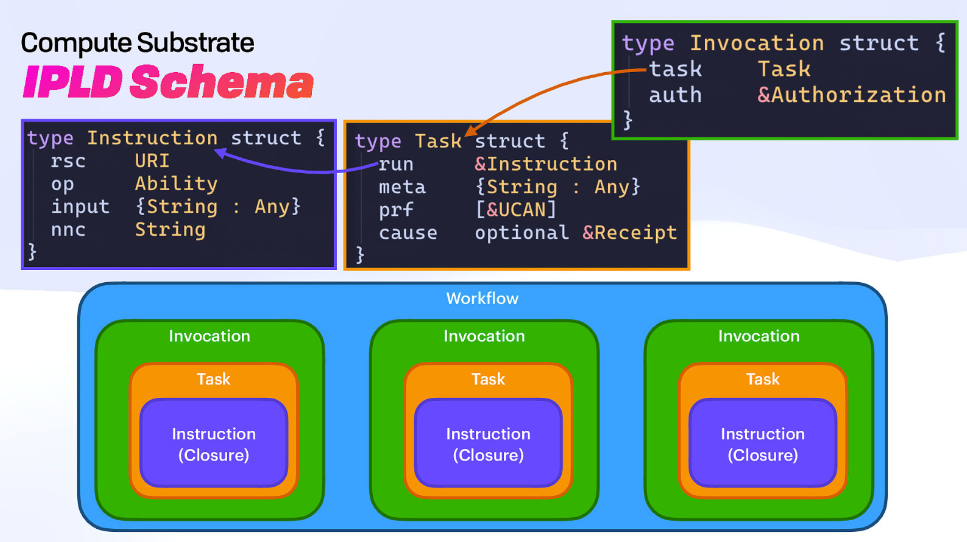
Here, we're introducing input addressing, where we get a receipt as the value, and the input is the hash of the instruction (the description of what you want to have run).
Instead of validating with a hash, we validate with a receipt, making it fully deterministic!
Finally, we use an invocation (a signature) and build a workflow (by authorizing multiple computation requests at once).
Benefits of Wasm Compute
- The distributed runtime can decide the most efficient way to run tasks in the network by handling the matchmaking for the user.
- The more returned receipts, the fewer computations we'll need to run. We can skip steps and reuse receipts because they've been deterministically run already.
- If the system crashes, you can always pick up where you left off by following the CID trail.
- Reverse lookup allows the user to check if a certain input ID has been entered. If it has, they can retrieve the computed result without running the task again. This is especially helpful when running AI language models over the same data or cryptographic operations.
Compute over Data Summit 2023 Presentation
These are all open standards and protocols, and you can get involved by joining the Compute over Data working group and/or the IPVM working group.